Anteriormente, a coleta de dados foi feita de forma 'rústica', usando uma máquina falha e limitada chamada: humanos! Isso implicou em um número reduzido de dados para uma análise mais substancial, além dos erros sistemáticos que provém de uma coleta manual. Por isso, com a ajuda da amada computação conseguimos coletar um número significativo de dados para uma análise mais profunda e representativa.
Com mais dados a expectativa é que o modelo anterior também descreva bem os novos dados para ser efetivado como o melhor modelo que descreve o comportamento de uma atividade no Facebook. Nos restringiremos a analisar o comportamento dos 'likes' a partir de agora.
Me dê o seu like!
Para a coleta de dados utilizamos um script que grava o número de likes ao longo de um determinado período de um post recém lançado. O post era sempre de alguém com uma quantidade expressiva de seguidores para que a quantidade de dados fosse bastante significativa. As celebridades que acompanhamos e que iremos usar para este trabalho foram: Cristiano Ronaldo, Justin Bieber e David Beckham. Após a coleta tentamos ajustar o modelo que propusemos anteriormente aos novos dados.
Ajuste dos dados com o modelo inicial
Vamos agora usar o nosso modelo anterior (1º ajuste) para verificar como este se ajusta aos dados coletados.
Ajuste dos dados do Justin Bieber


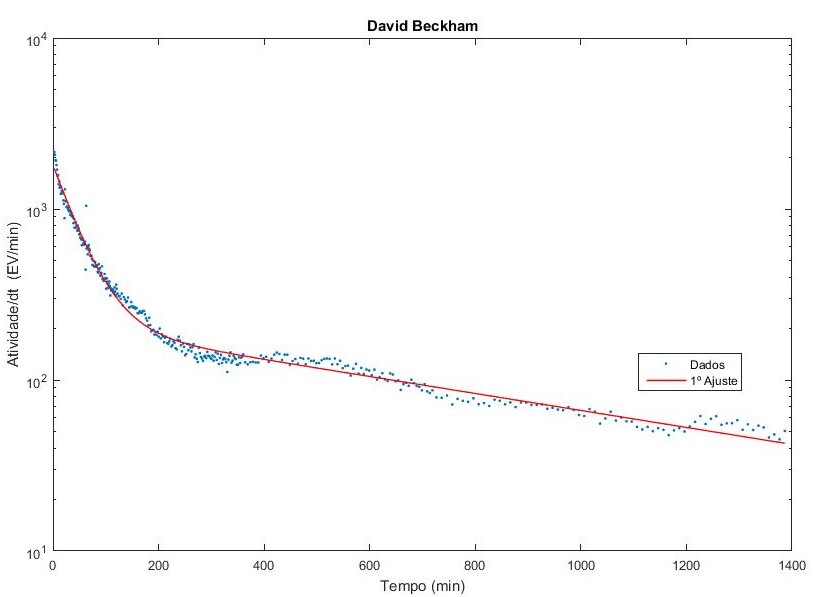
Percebemos com os ajuste que o modelo se adequa bem aos dados para tempos curtos, mas ao considerar um longo período este se mostra falho para descrever o comportamento dos dados após muitas horas. Triste realidade! Nesse caso, teremos que fazer uma modificação no modelo atual para tentar ajustar melhor os dados para tempos muito longos. Nos próximos capítulos dessa rede tentaremos ajustar os dados a um novo modelo.
Nenhum comentário:
Postar um comentário