Vamos conversar
Conversa entre um usuário de Facebook e a galera do blog.
[Usuário] Ok, você fizeram um ajuste (é essa a palavra?) com uma equação gigante, com um monte de gráficos coloridos, mas eu não entendi nada do que vocês quiseram dizer!
[Luane] Tá bom, vamos por partes: o que você não entendeu?
[Usuário] Se o ajuste com os lambdas estava bom, por que mudar pra uma equação menor?
[Luane] Bom, quanto maior o número de variáveis numa equação, maior é o erro de truncamento dos números no resultado final. Fica mais difícil de o computador calcular alguma coisa.
[Adriana] Fora que, se a gente depende de um monte de variável em um ajuste, isso quer dizer que os fatores que influenciam no comportamento do usuário são muitos. Para pra pensar: pra uma postagem aparecer na sua timeline, ela depende de que?
[Usuário] Não sei. O Facebook que escolhe algumas coisas, não? Eu curto algumas páginas também.
[Adriana] Certo, você curte algumas páginas e baseado nesse seu interesse o Facebook escolhe o que vai estar na sua timeline. Aparecem também coisas que seus amigos curtiram, não é?
[Usuário] Aparecem.
[Adriana] Então, eles tem um algoritmo que limita as variáveis que influenciam na escolha do que vai aparecer como sugestão de coisas pra você ver.
[Luane] Quanto mais você curte um assunto ou uma fanpage, mais vezes isso vai aparecer na sua timeline.
[Usuário] Ah tá, mas então aquele ajuste que vocês fizeram com um ezinho só é pouca coisa?
[Luane] A longo prazo ele diverge do que de fato acontece. Você viu que a gente acompanhou posts por alguns dias e que dá pra perceber a atividade caindo, mas não é um comportamento regular e igual pra todos os casos. Se a gente colocar variáveis demais ou de menos, a gente perde o que está acontecendo com o tempo porque tem um número certo de dependências.
[Adriana] E dá pra ver que o terceiro ajuste que a gente fez tem menos dependências, a gente perdeu muita informação pra tempos de amostragem mais longos.
[Usuário] Como assim dependências?
[Adriana] Cada variável da equação representa a dependência de um fator. Lembra quando a gente falou de como as coisas aparecem na timeline? Elas dependem de que páginas você curtiu, que páginas seus amigos curtiram ou ainda amigos de amigos. Fora os links patrocinados, fanpages patrocinadas e, em alguns casos, números muito altos de seguidores de uma determinada página. Cada coisa dessas tem um peso na hora de aparecer na sua timeline que influencia na visualização e curtidas de um post qualquer. Isso tudo gera diversas variáveis de dependência que a gente estava tentando verificar com esses ajustes.
[Usuário] Ah tá, mas e ai? O que quer dizer as variáveis do ajuste além do que vocês escreveram lá?
[Luane] Não dá pra saber o que exatamente quer dizer casa uma das variáveis sem saber como funciona exatamente o algoritmo do Facebook. Mas a gente conseguiu perceber que o comportamento geral, independente da quantidade de seguidores de uma fanpage, é igual!
[Adriana] Bora tomar uma breja que eu vou te contar como o Facebook e o colarinho da cerveja se comportam da mesma forma.
Menos é mais?
Vimos anteriormente que com lambdas adicionados na descrição conseguimos melhorar o ajuste. E se ao invés de duas exponenciais e dois lambdas colocarmos apenas uma exponencial e um lambda na nossa nova hipótese?
Terceiro Modelo:

Terceiro Modelo:

Ajustes
Ajuste dos dados do Justin Bieber
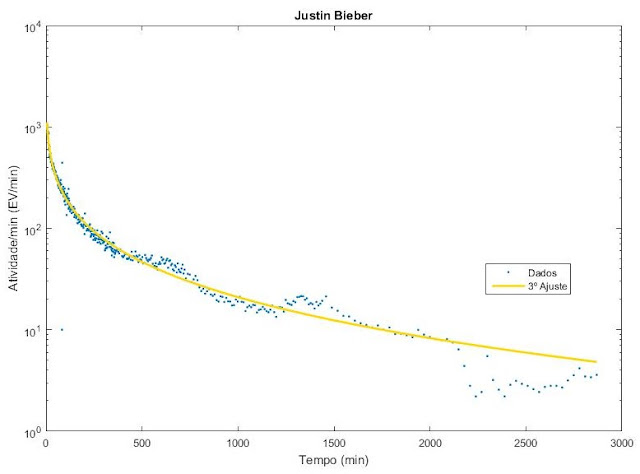

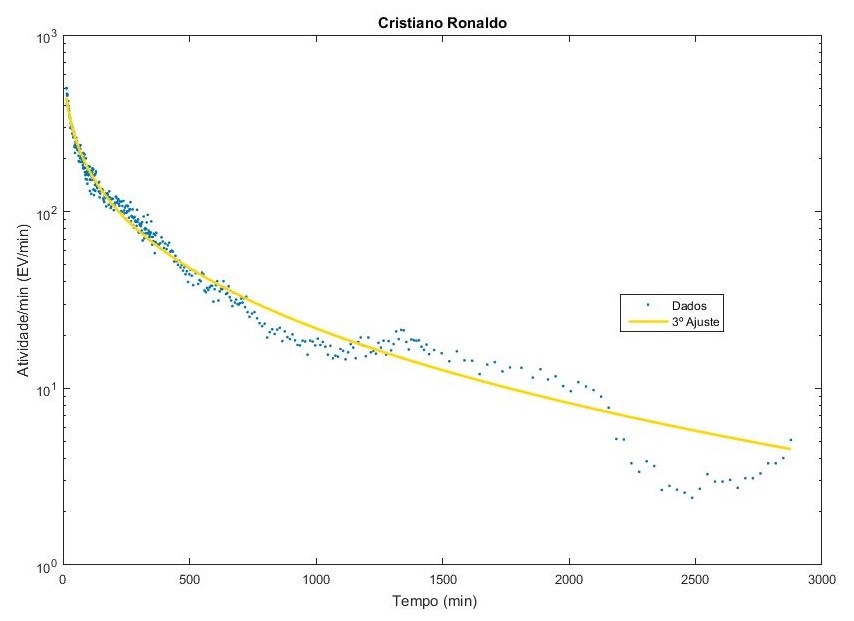
Ajuste dos dados do Cristiano Ronaldo

Ajuste dos dados do David Beckham

Comparativo - o juízo final
Comparativo - Justin Bieber


Comparativo - David Beckham

E nas passarelas: um novo modelo!
O nosso modelo inicial não se mostrou satisfatório, ou seja, precisa ser modificado para o bem da nossa análise!
Como nova proposta pensamos que acrescentar a cada exponencial um termo elevado, com isso, temos:








Como nova proposta pensamos que acrescentar a cada exponencial um termo elevado, com isso, temos:
O sentido do novo modelo tentaremos explicar, se conseguirmos, ao longo da nossa análise.

Ajustes com o novo modelo
Ajuste dos dados do Justin Bieber

Ajuste dos dados do Cristiano Ronaldo

Ajuste dos dados do David Beckham

Olhando por 'cima' temos a impressão de que o 2º ajuste descreve melhor os dados. Para ter certeza, só comparando não é mesmo?
Comparativo
Agora vamos comparar os dados para deixar claro qual modelo melhor se ajustou aos dados.
Comparativo - Justin Bieber

Comparativo - Cristiano Ronaldo

Comparativo - David Beckham

Com o comparativo conseguimos visualizar claramente que o nosso novo ajuste é melhor para descrever o comportamento de uma forma geral. Em todos os gráficos ele se mostrou mais adequado.
Em busca de uma solução minimalista
Nosso novo modelo se mostrou satisfatório? Sim! Descreveu de forma geral os dados? Sim! Então problema resolvido, né? Não! O fato do modelo ter se ajustado não significa que uma nova hipótese não possa ser levantada. Se encontramos uma solução que descreva os dados mas que tenha menos parâmetros (menos parâmetros, menos problemas!), podemos exprimir de forma mais simples o comportamento dos dados na nossa análise.
Continuemos...
Facebook: nada fácil de descrever
Voltamos para continuar nossa análise através dessa rede tão usada e complexa que é o Facebook. Nas postagens anteriores propusemos um modelo de comportamento e tentamos analisar as atividades com base nesse modelo, podendo assim falar com propriedade sobre relevância a respeito de postagens nessa rede social. De imediato concluímos que o modelo descrevia bem nossos dados e nos damos por satisfeitas. Porém nem tudo são flores, e se tratando de comportamento humano as coisas não são tão simples quanto possam parecer num primeiro momento.
Anteriormente, a coleta de dados foi feita de forma 'rústica', usando uma máquina falha e limitada chamada: humanos! Isso implicou em um número reduzido de dados para uma análise mais substancial, além dos erros sistemáticos que provém de uma coleta manual. Por isso, com a ajuda da amada computação conseguimos coletar um número significativo de dados para uma análise mais profunda e representativa.
Com mais dados a expectativa é que o modelo anterior também descreva bem os novos dados para ser efetivado como o melhor modelo que descreve o comportamento de uma atividade no Facebook. Nos restringiremos a analisar o comportamento dos 'likes' a partir de agora.
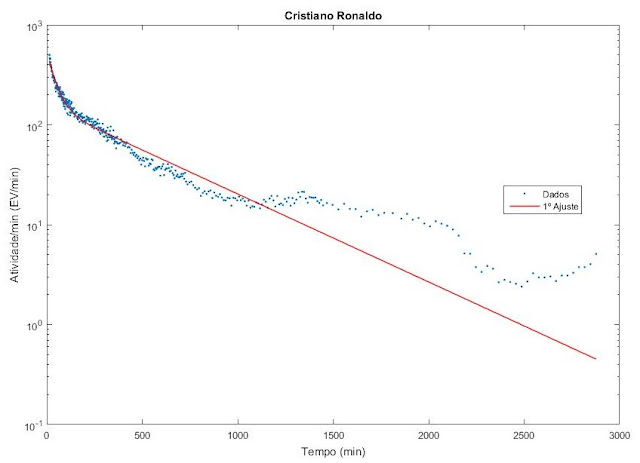
Para a coleta de dados utilizamos um script que grava o número de likes ao longo de um determinado período de um post recém lançado. O post era sempre de alguém com uma quantidade expressiva de seguidores para que a quantidade de dados fosse bastante significativa. As celebridades que acompanhamos e que iremos usar para este trabalho foram: Cristiano Ronaldo, Justin Bieber e David Beckham. Após a coleta tentamos ajustar o modelo que propusemos anteriormente aos novos dados.
 Ajuste dos dados do Cristiano Ronaldo
Ajuste dos dados do Cristiano Ronaldo
Ajuste dos dados do David Beckham
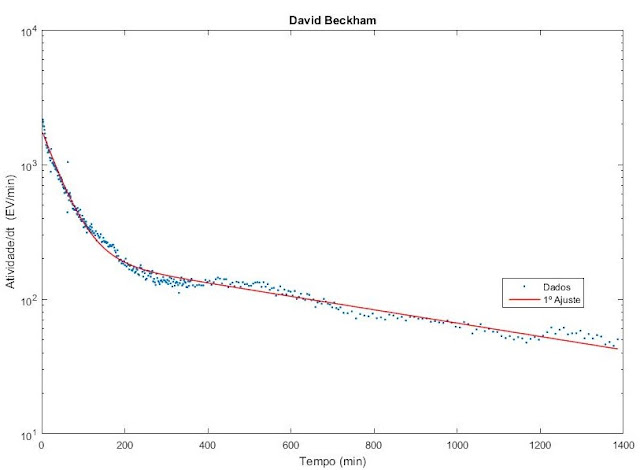
Percebemos com os ajuste que o modelo se adequa bem aos dados para tempos curtos, mas ao considerar um longo período este se mostra falho para descrever o comportamento dos dados após muitas horas. Triste realidade! Nesse caso, teremos que fazer uma modificação no modelo atual para tentar ajustar melhor os dados para tempos muito longos. Nos próximos capítulos dessa rede tentaremos ajustar os dados a um novo modelo.
Anteriormente, a coleta de dados foi feita de forma 'rústica', usando uma máquina falha e limitada chamada: humanos! Isso implicou em um número reduzido de dados para uma análise mais substancial, além dos erros sistemáticos que provém de uma coleta manual. Por isso, com a ajuda da amada computação conseguimos coletar um número significativo de dados para uma análise mais profunda e representativa.
Com mais dados a expectativa é que o modelo anterior também descreva bem os novos dados para ser efetivado como o melhor modelo que descreve o comportamento de uma atividade no Facebook. Nos restringiremos a analisar o comportamento dos 'likes' a partir de agora.
Me dê o seu like!
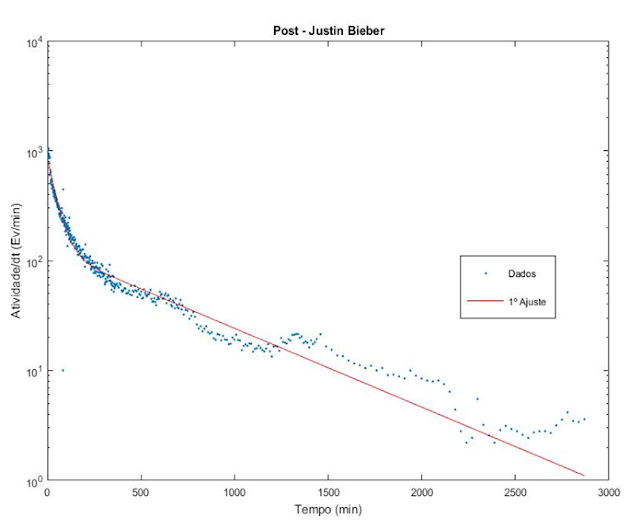
Para a coleta de dados utilizamos um script que grava o número de likes ao longo de um determinado período de um post recém lançado. O post era sempre de alguém com uma quantidade expressiva de seguidores para que a quantidade de dados fosse bastante significativa. As celebridades que acompanhamos e que iremos usar para este trabalho foram: Cristiano Ronaldo, Justin Bieber e David Beckham. Após a coleta tentamos ajustar o modelo que propusemos anteriormente aos novos dados.
Ajuste dos dados com o modelo inicial
Vamos agora usar o nosso modelo anterior (1º ajuste) para verificar como este se ajusta aos dados coletados.
Ajuste dos dados do Justin Bieber


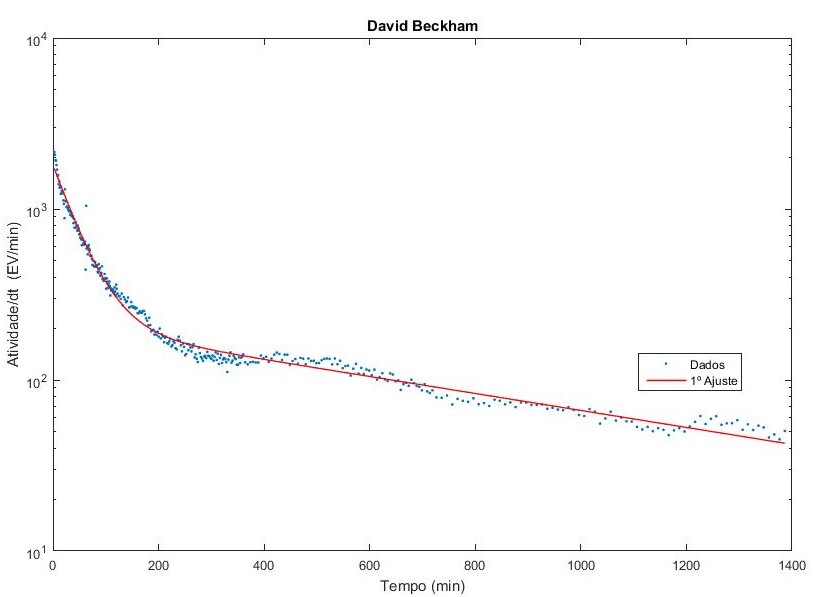
Percebemos com os ajuste que o modelo se adequa bem aos dados para tempos curtos, mas ao considerar um longo período este se mostra falho para descrever o comportamento dos dados após muitas horas. Triste realidade! Nesse caso, teremos que fazer uma modificação no modelo atual para tentar ajustar melhor os dados para tempos muito longos. Nos próximos capítulos dessa rede tentaremos ajustar os dados a um novo modelo.
Assinar:
Postagens (Atom)